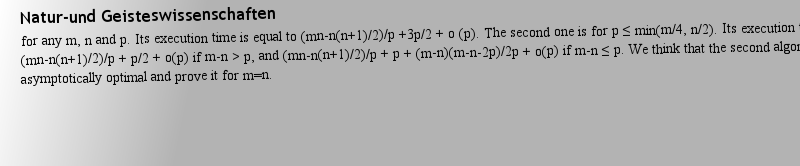標題: Titlebook: CONPAR 90 - VAPP IV; Joint International Helmar Burkhart Conference proceedings 1990 Springer-Verlag Berlin Heidelberg 1990 Debugging.Scal [打印本頁] 作者: 熱情美女 時間: 2025-3-21 18:08
書目名稱CONPAR 90 - VAPP IV影響因子(影響力)
書目名稱CONPAR 90 - VAPP IV影響因子(影響力)學科排名
書目名稱CONPAR 90 - VAPP IV網(wǎng)絡公開度
書目名稱CONPAR 90 - VAPP IV網(wǎng)絡公開度學科排名
書目名稱CONPAR 90 - VAPP IV被引頻次
書目名稱CONPAR 90 - VAPP IV被引頻次學科排名
書目名稱CONPAR 90 - VAPP IV年度引用
書目名稱CONPAR 90 - VAPP IV年度引用學科排名
書目名稱CONPAR 90 - VAPP IV讀者反饋
書目名稱CONPAR 90 - VAPP IV讀者反饋學科排名
作者: calamity 時間: 2025-3-21 22:05 作者: allergy 時間: 2025-3-22 01:11 作者: 集中營 時間: 2025-3-22 06:05
A novel paradigm of parallel computation and its use to implement simple high performance hardware,s than known from von Neumann computers. Acceleration factors of up to more than 2000 have been obtained experimentally on the MoM architecture for a number of important applications — although using a processor hardware being more simple than that of a single RISC microprocessor. The most important作者: 上下連貫 時間: 2025-3-22 11:04 作者: 投票 時間: 2025-3-22 14:59
A model for performance prediction of message passing multiprocessors achieving concurrency by domaition i.e., by partitioning the data domain into sub-domains, computation on each of which is carried out on a different processor..Studies on different numerical algorithms reveal that execution of an algorithm can be modelled as repetitive cycles where a cycle consists of computation followed by c作者: 投票 時間: 2025-3-22 19:17
Workloads, observables, benchmarks and instrumentation,onships among a limited number of major system resources that determine most performance variance. This new approach is especially effective with hardware instrumentation that decouples workload from observation (otherwise, a compact set of observables may be unavailable). A tree supports simple pre作者: 過于光澤 時間: 2025-3-22 22:13 作者: 木訥 時間: 2025-3-23 01:46
Divide and conquer: A new parallel algorithm for the solution of a tridiagonal linear system of equ The algorithm is very flexible, permits multiprocessing or a combination of vector and multiprocessor implementations, and is adaptable to a wide range of parallelism granularities. This algorithm can also be combined with recursive doubling, cyclic reduction or Wang‘s partition method, in order to作者: CBC471 時間: 2025-3-23 07:34 作者: 熱烈的歡迎 時間: 2025-3-23 11:49
Parallel givens factorization on a shared memory multiprocessor,trices [6]. For the rectangular case the problem of the optimality (construction and execution time of the optimal algorithm) is still open. In this paper we describe two parallel algorithms to compute the Givens factorization of a rectangular matrix of size mxn (m ≥ n). The first one is formulated 作者: 截斷 時間: 2025-3-23 13:55 作者: cartilage 時間: 2025-3-23 18:41
Parallel implementation of logic languages,roach in which, a logic program is translated to obtain processes that are look-alike Occam programs implementable on any platform that supports extended Occam. Besides the use of an intermediate language, the other main features of this implementation are作者: 起草 時間: 2025-3-24 01:39 作者: Pruritus 時間: 2025-3-24 04:53
The ELAN performance analysis environment,urement equipment for program observation as well as for performance and loss-analysis in a multiprocessor system. In this paper first some basic notions and a classification of all sources of performance loss in a multiprocessor are given. Then we present an experimental environment which comprises作者: 四牛在彎曲 時間: 2025-3-24 10:23 作者: 債務 時間: 2025-3-24 13:01
An adaptive blocking strategy for matrix factorizations,lock algorithms have been successful for matrix computations. By considering a matrix as a collection of submatrices (the so-called blocks) one naturally arrives at algorithms that require little data movement. The optimal blocking strategy, however, depends on the computing environment and on the p作者: 不舒服 時間: 2025-3-24 16:12
0302-9743 r market segments in scientific computing. The 1990s are likely to become the decade of parallel processing. .CONPAR 90 - VAPP IV. is the joint successor meeting of two highly successful international conference series in the field of vector and parallel processing. This volume contains the 79 paper作者: Resection 時間: 2025-3-24 19:10
https://doi.org/10.1007/978-3-322-85929-7number of important applications — although using a processor hardware being more simple than that of a single RISC microprocessor. The most important hardware features of xputer will be briefly introduced. By means of 2 simple algorithm examples the programming paradigm and its flexibility will be illustrated.作者: abstemious 時間: 2025-3-25 00:58
A novel paradigm of parallel computation and its use to implement simple high performance hardware,number of important applications — although using a processor hardware being more simple than that of a single RISC microprocessor. The most important hardware features of xputer will be briefly introduced. By means of 2 simple algorithm examples the programming paradigm and its flexibility will be illustrated.作者: deciduous 時間: 2025-3-25 03:43 作者: AMBI 時間: 2025-3-25 09:01 作者: Canopy 時間: 2025-3-25 15:28
Natur-und Geisteswissenschaften increase the degree of parallelism and vectorizability..The divide and conquer method will be explained. Some results of time measurements on a CRAY X-MP/28, on an Alliant FX/8 and on a Sequent Symmetry S81b as well as comparisons with the cyclic reduction algorithm and Gaussian elimination will be presented.作者: MARS 時間: 2025-3-25 16:46 作者: 持久 時間: 2025-3-25 23:17
Natur-und Geisteswissenschaftenmance evaluation. The tool environment for evaluating event traces, which integrates the data access interface TDL/POET and a set of evaluation tools for processing the data, makes evaluation independent of the monitor device(s) and the object system. It provides a problem oriented way of accessing event traces.作者: 熱烈的歡迎 時間: 2025-3-26 01:56
Natur-und Geisteswissenschaften and extends some already existing tools and is aimed to (semi-)automatize performance- and loss-analysis on the M.-multiprocessor. For clarification and concreteness we also included a few examples of such analyses and some notes on implementation aspects of ELAN.作者: 阻塞 時間: 2025-3-26 04:29 作者: 疾馳 時間: 2025-3-26 09:36 作者: SEED 時間: 2025-3-26 15:48 作者: 平淡而無味 時間: 2025-3-26 20:44 作者: 無思維能力 時間: 2025-3-26 22:34 作者: 侵略者 時間: 2025-3-27 04:01
Workloads, observables, benchmarks and instrumentation,dictions and promotes more meaningful comparisons of workloads. Accounting for the sources of performance variation shown in the tree can inspire new methods of assessment; a "time dilation" technique illustrates this for loosely-coupled systems with local clocks.作者: 肉體 時間: 2025-3-27 09:20
Divide and conquer: A new parallel algorithm for the solution of a tridiagonal linear system of equ increase the degree of parallelism and vectorizability..The divide and conquer method will be explained. Some results of time measurements on a CRAY X-MP/28, on an Alliant FX/8 and on a Sequent Symmetry S81b as well as comparisons with the cyclic reduction algorithm and Gaussian elimination will be presented.作者: cardiovascular 時間: 2025-3-27 11:29 作者: Palatial 時間: 2025-3-27 13:51 作者: synovium 時間: 2025-3-27 21:47 作者: acetylcholine 時間: 2025-3-28 00:22 作者: Alpha-Cells 時間: 2025-3-28 04:51 作者: 灰心喪氣 時間: 2025-3-28 09:59
https://doi.org/10.1007/978-3-642-95614-0its entries are zero. We show how direct algorithms based on Gauss Elimination and semi-iterative algorithms (Conjugate Gradient Methods) can be implemented on SUPRENUM. Especially the Conjugate Gradient Methods which are very well suited for parallelization and vectorization proved to be very efficient on multiprocessor architectures.作者: 損壞 時間: 2025-3-28 10:44
Presto: A bus-connected multiprocessor for a rete-based production system,two kinds of newly developed ASIC chips which engage in memory control and bus control, respectively. Hierarchical system software is provided for interpreter program development. Performance measurement with 10 PEs demonstrates that sample programs run 5–7 times faster.作者: Legion 時間: 2025-3-28 15:57
Sparse matrix algorithms for SUPRENUM,its entries are zero. We show how direct algorithms based on Gauss Elimination and semi-iterative algorithms (Conjugate Gradient Methods) can be implemented on SUPRENUM. Especially the Conjugate Gradient Methods which are very well suited for parallelization and vectorization proved to be very efficient on multiprocessor architectures.作者: labyrinth 時間: 2025-3-28 20:50 作者: VERT 時間: 2025-3-28 23:14
Prolog implementations on parallel computers,In this paper two research projects are overviewd. The first intended to explore the possibility of implementing Prolog on a typical SIMD machine, called Distributed Array Processor (DAP). The second project focusses on systolic arrays and proposes a special wavefront array for parallel unification in logic programming languages.作者: nonsensical 時間: 2025-3-29 07:01 作者: 大廳 時間: 2025-3-29 10:15 作者: 蚊子 時間: 2025-3-29 13:09 作者: 隨意 時間: 2025-3-29 18:52 作者: alcohol-abuse 時間: 2025-3-29 23:27 作者: DEI 時間: 2025-3-30 03:55 作者: 規(guī)范就好 時間: 2025-3-30 06:52 作者: 省略 時間: 2025-3-30 11:04
Rollende und fliegende Bewegungocessor configuration depends on the given problem, too. To decide which implementation for any configuration may be the best, the programmer can use methods of performance evaluation and prediction. If the structure of the parallel program can be modeled by a seriesparallel graph we know a method t作者: Instantaneous 時間: 2025-3-30 14:28 作者: START 時間: 2025-3-30 18:33
https://doi.org/10.1007/978-3-642-95614-0rocessor system was delivered late in 1989 for the first time. It is the result of a research project where German research institutes, universities and industrial companies worked together to built a 256 processor distributed memory machine. In parallel with the construction of the SUPRENUM a lot o作者: 玩忽職守 時間: 2025-3-30 23:56 作者: BOOM 時間: 2025-3-31 01:36
Natur-und GeisteswissenschaftenR-Parallelism. The RAP/LOP-WAM is based on the OR-forest description. It handles Restricted AND-Parallelism through procedure-level and clause-level analysis at compiler-time, and simple run-time checks to identify independent goals of the body of a clause. It exploits OR-parallelism under the limit作者: WITH 時間: 2025-3-31 07:22 作者: 注視 時間: 2025-3-31 12:33
Natur-und Geisteswissenschaftenmodel is introduced for describing the dynamic behavior of computer systems in terms of events. Then, a distributed hardware/hybrid monitor system based on event driven monitoring and its tool environment SIMPLE are presented. We emphasize the tool environment as a prerequisite for successful perfor作者: 使?jié)M足 時間: 2025-3-31 14:35
Natur-und Geisteswissenschaftenurement equipment for program observation as well as for performance and loss-analysis in a multiprocessor system. In this paper first some basic notions and a classification of all sources of performance loss in a multiprocessor are given. Then we present an experimental environment which comprises作者: 花束 時間: 2025-3-31 20:42
https://doi.org/10.1007/978-3-642-95614-0. NETMON-II is a distributed monitoring tool, which is especially suited for monitoring and debugging multiprocessor systems such as Transputer networks. It was developed with the special goal of least possible interference with the monitored object. The monitoring system itself is distributed, whic作者: debase 時間: 2025-3-31 22:06
https://doi.org/10.1007/3-211-28252-1lock algorithms have been successful for matrix computations. By considering a matrix as a collection of submatrices (the so-called blocks) one naturally arrives at algorithms that require little data movement. The optimal blocking strategy, however, depends on the computing environment and on the p